A pi extension that gives the agent two essential capabilities — searching the web and reading pages — without API keys, accounts, or a headless browser. Just ddgr and pandoc running locally on your machine.
Features
websearch: DuckDuckGo search viaddgr. Up to 25 results with title, URL, and snippet. Region and safesearch controls.webfetch: HTTP fetch + HTML→markdown conversion viapandoc(preferred) orw3m(fallback). Auto-handles Cloudflare UA challenges.- Reader-View extraction: Optional
trafilaturaorrdrviewpre-pass strips nav, sidebars, and footers. Typically 5–20× smaller output on chrome-heavy pages (GitHub, MDN, Stack Overflow). - Charset-aware: Honors
Content-Typecharset and sniffs<meta charset>— handleswindows-1250,shift_jis,gb2312, and friends correctly. - Safe by default: SSRF blocked (localhost, RFC1918, link-local). 5 MB response cap. 30s timeout. Read-only and synchronous.
Design Philosophy
- Shell-only: No headless browser, no JS execution. If the site needs JS, use its REST/RSS/JSON endpoints instead.
- Zero state: No cache, no accounts, no telemetry. Each call is independent.
- No per-host magic: No
if hostname === "github.com"branches. Site-specific behavior belongs in personal pi skills, not in this package. - Bar for new tools is high: Two tools, both general-purpose. New surface area requires justification.
Install
System dependencies (one-time):
brew install ddgr pandoc # macOS
# or: pip install ddgr; apt install pandoc w3mInstall the extension from npm:
pi install npm:@bitcraft-apps/pi-web-toolsFor a richer extraction pipeline, also install one of:
pipx install trafilatura # recommended; works everywhere with Python
# rdrview as an alternative — see github.com/eafer/rdrviewRestart pi and the websearch and webfetch tools become available to the agent.
Usage
You don’t call these tools directly — pi’s agent picks them up when it needs web context:
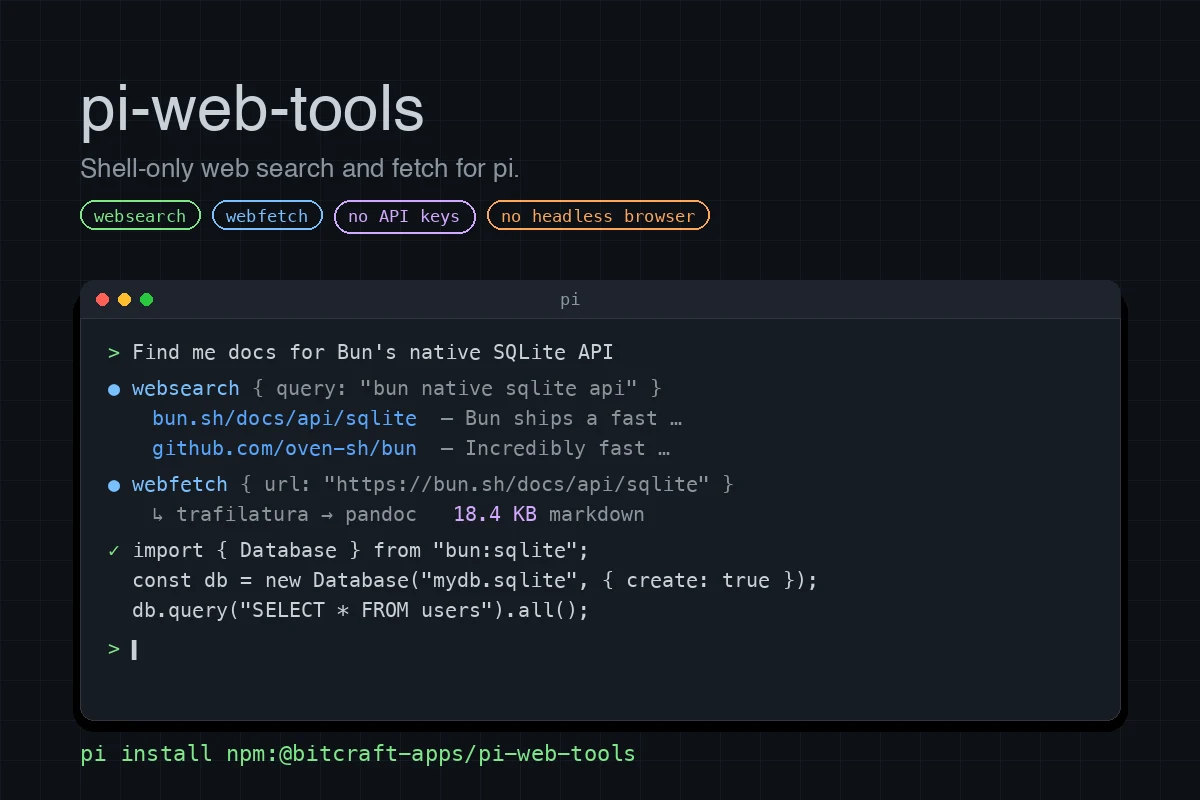
> Find me docs for Bun's native Sqlite API
[agent uses websearch → gets bun.sh URL → uses webfetch → reads docs]Limitations
- JS-heavy SPAs return empty markdown. Workarounds:
old.reddit.com,*.jsonAPI endpoints, RSS/Atom feeds. - DuckDuckGo rate limits are low and unspecified. If
websearch429s, wait or usewebfetchagainst a known URL. - PDFs, images, audio, video are not fetchable — text/HTML only.